サイト内の現在位置を表示しています。
個人データを巡る諸課題とEU一般データ保護規則(GDPR)における解決の方向性
2018年10月2日、「個人データを巡る諸課題とEU一般データ保護規則(GDPR)における解決の方向性」と題して、IISE 調査研究部 主幹研究員の小泉雄介が講演を行った。以下は講演内容の抄録。
1.はじめに
3年前にパーソナルデータについてご報告させていただいたが、今回はそのアップデートとして、前半ではEUの一般データ保護規則(GDPR)の概要について、後半では個人データを巡る現代の諸課題とGDPRにおける解決の方向性についてご説明したい。
2. EU一般データ保護規則(GDPR)の概要
全世界規模での個人情報保護制度の見直しについて
データ保護制度の見直しや整合化がEUのみならず全世界で進んでいる。個人データを取り巻く環境変化がその背景にある。急速なICT技術の進展、グローバル化の進展によって、個人の権利や利益を侵害されるリスクが拡大している。個人データの取得手段が高度化し、スマートフォンや監視カメラ、ウェアラブル端末等を通じて個人に関するデータが大量かつリアルタイムに取得可能になっているからだ。個人が自らのデータをSNS等で公開したり、共有化したりする動きも増えている。クラウドコンピューティングによって越境データの流通も増えている。個人データがあちらこちらから大量に集められ、利用されることでデータ乱用や漏えいのリスクが常在している。
アメリカのプラットフォーム企業と呼ばれるグーグル、フェイスブック、アマゾンなどの存在も大きい。個人データを含めた質の高い大量データこそが人工知能強化の鍵と言う風に言われており、彼らは世界各地から大量の個人情報を収集している。米国政府は裏で彼らのデータにアクセスできるという事が2013年のスノーデン事件で暴露されたが、民間企業と政府が一体となって個人情報を収集し、監視にも使われているということが明るみになったことのインパクトは大きい。アメリカには古くからプライバシー法があったが、連邦政府機関のみを規制対象としており、医療、金融、教育等を除き民間分野については自主規制が中心であった。当然グーグル、フェイスブックと言った一般の企業はプライバシー法の規制対象外であった。ところが今年6月にカリフォルニア州で消費者プライバシー法が成立した。これには昨今のフェイスブックの事件、つまりケンブリッジ・アナリティカ社へのデータの第三者提供が明るみになったことで、消費者の声が高まって議員立法に至ったという背景がある。つい先日(今年9月)にも、商務省の国家電気通信情報庁(NTIA)が民間分野の規制に関するパブコメを開始(10月26日まで受付)しており、ここでは民間分野での包括的規制の必要性を市民に問うている。カリフォルニア州で法律が出来たことで「アメリカ全体で法規制が乱立し、整合が取れなくなると困る」という業界からの意向を受けてのことだ。つまりアメリカでも、民間企業や業界団体が法規制に賛同するという今までは考えられなかった動きが出てきているのだ。
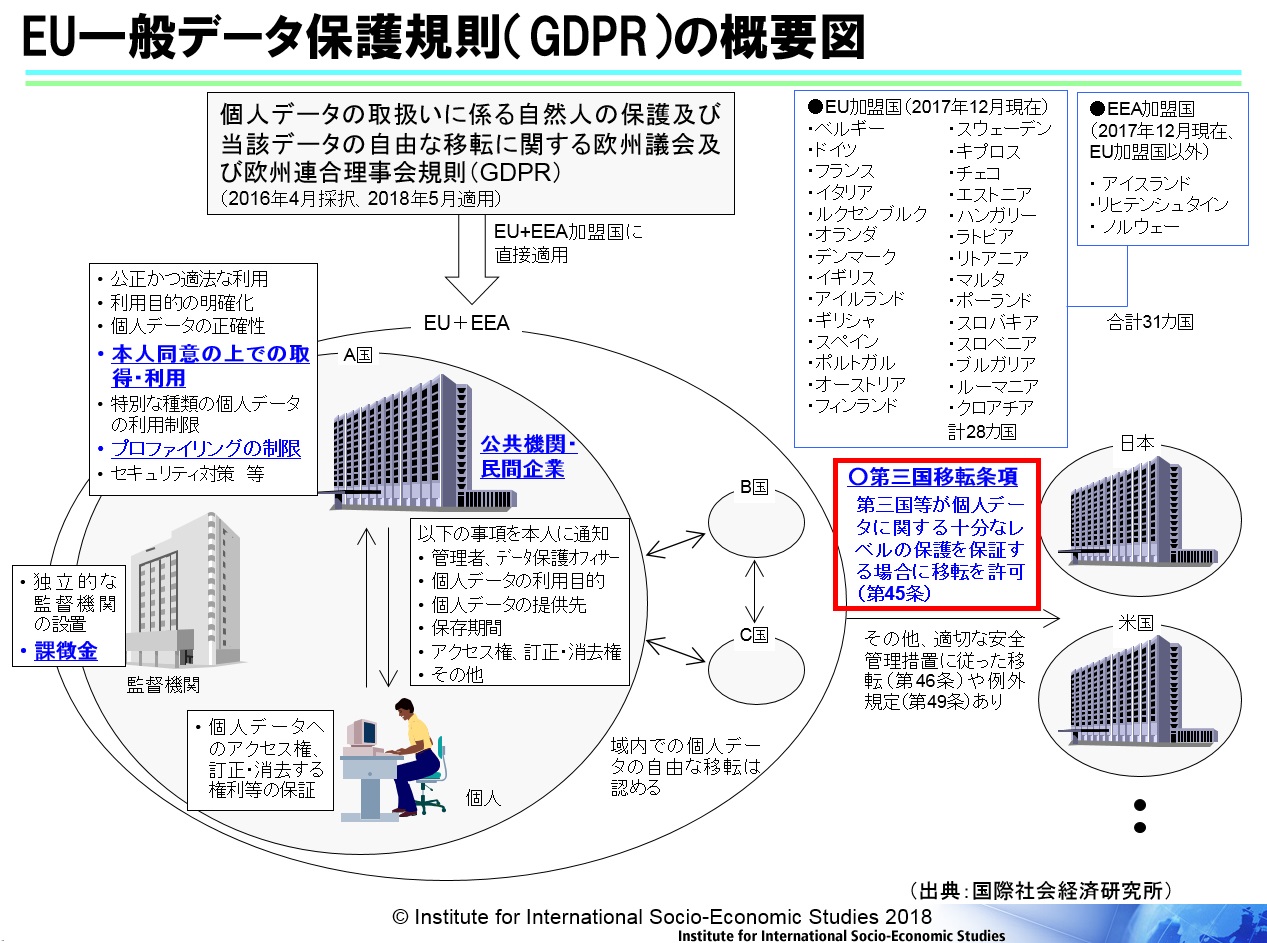
そうした世界的な環境変化の中で、EUでも今年5月から一般データ保護規則(GDPR)の適用が始まった。対象はEU加盟国(28)とEEA加盟国(3)のあわせて31か国だ。前身のEUデータ保護指令(EU指令)が採択されたのは23年前、1995年のことだが、今回「指令」から「規則」へと格上げされたことにより、加盟各国でバラバラであったデータ保護に関する国内法が基本的にはGDPRに一元化された。多国籍企業にとっては法を守るためのコスト削減につながるだろ。

GDPRの全体像と第三国移転条項について
今回の主題であるEUのGDPRは11章(第99条)から構成されており、EU指令に比べて全体的にデータ保護に関する個人の権利が強化されている。

GDPRでは、個人データについての十分なレベルの保護を保証しない限り、日本のような第三国がEU域内から外に個人データを移転することができない。EU域内に所在する日本企業の現地法人はもちろん規制対象だが、日本に所在する日本企業についてもEUに所在する個人のデータを商品・サービス提供に際してオンライン等で取得する場合であればGDPRが適応される。ただし、日本企業がEU企業からの提供や委託を受けて個人データを受け取る場合には、GDPR全体が適用されるというわけではなく「第三国移転条項」という箇所のみが適応される。

第三国移転条項とは、4つの条件(①「十分性認定」、②米国のセーフ・ハーバー・スキームの後継「プライバシー・シールド」、③「適切な安全管理措置」、④「本人による明示的な同意」等)のいずれかを満たす場合に、第三国へのデータ移転が可能になるというルールである。現時点で日本は、③に該当する「標準データ保護条項(略称SCC)」という措置を取るか、④の「本人同意」を得る必要がある為、EUからのデータ移転は非常にやりいくいが、今年12月には①の「十分性認定」を取得できる見込となっている。
日本の個人情報保護法との相違点
GDPRは、日本の個人情報保護法と基本的には似ているが、いくつか大きな違いもある(下記図表の下線部分を参照)。例えばGDPRでは、個人データは基本的には本人同意の上で取得・利用しなければならない。プロファイリングに対する制限もある(後述)。法に違反した場合、監督機関による課徴金が非常に高額なことも日本にない特徴だ。さらに日本の個人情報保護法は民間分野だけが対象だが、GDPRは公共機関も対象となっていることなどが大きな相違点だ。
3. 個人データを巡る諸課題とGDPRにおける解決の方向性
ここでは個人データに関する現代的な課題3つ、すなわち①「同意原則」の形骸化、②監視社会化、③ビッグデータ・AIにおける新たなプライバシー問題について、GDPRでどのように対応しているかを説明しよう。

①同意原則の形骸化とその解決策について
近年、企業のプライバシーポリシーの文章量が膨大になっており、読み手の「クリック・トレーニング」と言う言葉があるほど読みにくく、読むのが面倒で安易に「同意」してしまうという問題、すなわち「同意の形骸化」が常態化し問題となっている。あるEUの調査によると、消費者が自分の関係するサービスの契約約款全部に目を通すとしたら1か月/年間は必要だという結果が出ている。企業側が「きちんと伝えよう」という意図で詳しく書けば書くほど、読み手は自分のデータの取り扱われ方についてプライバシーポリシーを読んでも理解できなくなる。企業が個人の権利を守ろうとすればするほど、個人の負担が大きくなるというジレンマに陥っている。

前者について具体的には(1)複雑なプライバシーポリシーであっても出来る限り「分かりやすく伝える仕組み」を提供しなさいということ(第12条:透明性)、(2)個人へ「コントロール」手段を提供しなさいということ、すなわち一旦「同意」の上で企業にデータが渡ってしまったとしても「後で個人がデータを取り戻したり、消去できたりするような手段」を提供しなさいということ(第17条:忘れられる権利、第20条:データ・ポータビリティの権利)、こういった点がGDPRで示されている。
後者については、(3)企業は「プライバシー・バイ・デザイン(PbD)」と言う哲学を持って個人のプライバシーに事前に配慮しなさいということ(第25条:データ保護バイデザイン、第35条データ保護影響評価)、(4)個人と企業の間にデータ利用に関する共通の理解が存在する限りにおいて「コンテキスト」を尊重してよいということ(第6条1(f):正当な利益)などが示されている。例えば、ショッピングサイトで何かを買った後にお知らせが送られる事について「メールでダイレクト・マーケティングをやってよい」という事まで事前に同意がなかったとしても、その位であれば「共通理解がないとは言えない」と解釈し、本人合意がなくても良いというのが「コンテキストの尊重」に当たる。
②監視社会化とその解決策について
インターネットのみならずリアル世界でも個人情報の収集が広がっている。監視カメラ、ボディカメラ、ドローン、生体認証(顔・指紋・虹彩・音声等)、IDカード(政府・民間)、ソーシャル・ロボット、IOT機器(スマートフォン・AIスピーカー)など、こういった手段は特に個人の行動を追跡できてしまうことから「サーベイランス(監視)技術」と呼ばれている。従来であれば監視主体は政府機関が中心であったが、インターネットが普及した1990年代以降は民間企業、とりわけGAFAに代表されるプラットフォーム企業が、国境を越えて大量の個人情報を取得して問題となっている。スノーデン事件によって特に米国ではこのことが表面化した。行政機関と民間インターネット企業が手を組み、いわゆる「ビッグブラザー」として世界中の個人から莫大な量の個人情報を取得することが可能となってきた。

アマゾンやグーグルのAIスピーカは、マイクが常時オンになっている。例えばアマゾンでは「アレクサ」と話しかけるとその時点で個人データの収集もオンになる。アマゾンによれば、アレクサと呼びかけるまでは「個人データは取得しない」という事である。

監視社会化についての解決策としてGDPRで示しているのが「忘れられる権利(第17条)」と「データ・ポータビリティの権利(第20条)」の2つである。
忘れられる権利については、従来のEU指令にも「自分のデータを消去する権利」という規則があったが、GDPRではそれがさらに強化されており、本人が同意を撤回した場合に管理者は無条件で個人データを消去するか匿名化するかしなければならない。日本の個人情報保護法よりも厳しい規定である。2014年にスペイン人が原告となり、忘れられる権利が最初に認められた判例がある。原告は自分の名前をグーグルで検索すると過去のやましい記事が出てきてしまうことから、現地の新聞社に対する記事の削除と、スペインのグーグル社に対して検索結果での記事非表示を求め訴訟を起こした。新聞社への請求は却下されたが、グーグルに対する請求は認められた。欧州司法裁判所の判決では「検索エンジン事業者は、検索結果を表示するだけであっても消去請求に応じる義務がある」といったことが示された。もう一方のデータ・ポータビリティの権利とは、サービス提供者から自分の個人データをマシン・リーダブルな形で入手したり、誰にも妨害されずに他のサービスに移転したりすることができる権利のことだ。EUが、アメリカのフェイスブック等ソーシャルネットメディアに対抗する為に作られた権利だとも言われている。
③ビッグデータ・AIにおける新たなプライバシー問題とその解決策について>
ビッグデータ・AIにおいては、(1)「プロファイリング」、(2)「差別の助長」、(3)「自動意思決定」、(4)「予測データの正確性」というプライバシー等に関する新たな課題がでてきている。
(1)プロファイリングとは、ある人物についての既知の情報から、その人物の既知ではない情報について推定したり、将来の行動やリスクについて予測したりすることである。例えばアマゾンのようなネット通販での購買履歴から、趣味嗜好、年収、人種、健康状態などを推測するのもプロファイリングであり、現代社会では「行動ターゲッティング」として一般的に使われている技術で珍しいものではない。米国のスーパーマーケットTarget社の事例(購買履歴からの妊娠推測)は有名だ。フェイスブックの「いいね」ボタンと検索履歴などの組み合わせで、男性の性的指向(88%)、民族・人種(95%)、宗教(82%)を高確率で予測した研究もある。顔写真の特徴点から本人の信念や政治的見解、健康状態、性的指向を推測するプログラムが既に存在しているとも言われている。要するにビッグデータやAIによって推測制度がどんどん上がってきていることが問題となっている。精度が100%近くなってくると、推測データが本当のデータと同等のモノになっていくからだ。いくら本人が「自分の年収を教えたくない」と言って隠したり拒否したりしても、プロファイリングによって迂回的な情報の取得が可能になるからだ。そうした迂回的な取得によって、センシティブ情報、要配慮個人情報が推測される場合には、プライバシーの侵害にもつながる。
プロファイリングについての解決策として、GDPRでは「推測された個人情報」であっても、通常の「個人データの取得」と同等に取扱い、本人の明示的同意などの措置が必要とのガイドラインを示している。日本の個人情報保護法では、通常の個人情報から、要配慮個人情報を推測することは、要配慮個人情報の取得には当たらないといった見解、学説が有力となっている。
(2)ビッグデータ・AIにおいては、「差別の助長」と言う問題もある。AIのアルゴリズムや機械学習データにバイアスが含まれることで、社会的な差別が助長されたり、生み出されたりする恐れがある。AI自身は機械学習用データにどんなバイアスが含まれていたとしても、自らそのバイアスを回避することができない。設計者たる人間も、その人がもともと持っているバイアス・無意識的なバイアスの場合は、気付くことが難しい。

GDPRでは、このような問題に対処するためにバイアスの存在をチェックするための定期的なシステムの評価やアルゴリズム監査を推奨している。アルゴリズム監査では、機械学習によって使用され開発されたアルゴリズムをテストし、それらが意図されたとおりに実際に動いており、差別的、誤りのある、あるいは正当化できない結果を生み出していないことを証明することが重要だとしている。
(3)日本でもAIによる自動意思決定が端緒についた。例えばソフトバンクは新卒採用のエントリーシート選考にIBMのAI「Watson」を使っている。ソニー銀行では2018年5月から住宅ローンの仮審査において独自に開発したAIを活用している。リコーリースでも2018年1月から少額リース案件のうちの1割程度(3~5千件)をAIによる自動審査に切り替えたという。
しかし、もしAIによる自動意思決定によって採用や審査に落ちてしまった場合、個人は不利な結果に素直に従うしかないのだろうか。この点についてGDPRでは、本人に法的効果や重大な影響をもたらすような自動意思決定は原則として禁止しており(第22条)、本人の明示的な同意等によって例外的に許される場合であっても、「人を介在させる権利」、「自分の見解を表明する権利」、「決定に異議を唱える権利」を保障することが求められている。特別な種類の個人データ、センシティブデータに基づく意思決定はもちろん禁止だ。人の介在については、少しだけ間に入っているだけではだめで、本人の申し立てに対して意思決定を変更する適切な権限と能力を持った人間によって実施されないといけないと明言されている。
(4)予測データの正確性が問題になることもある。年齢や性別などの事実データを推測するのであればさほど問題とならないが、病気の罹患リスク、犯罪予測、遺伝子によって人の将来を予測するといったようなケースにおいては、「予測データ」が正確か否かは判断しにくい場合があり問題となりうる。例えば心臓病の罹患リスクが高いと予測された人が、5年経っても10年経っても心臓病にかからなかった場合どうなるのか。予測データのために高額な保険料を支払っていたり、保険加入を拒否されていたりする場合、データの訂正を求めることはできるのだろうか。
この点についてGDPRでは(そして日本の個人情報保護法でも)、「事実データ」が不正確な場合は本人の請求により訂正することができる(第17条)。これは個人の権利として保障されている。しかし「予測データ」については、その「正確性の意味」がまず問われることとなる。この点はEUでも議論になっているとのことである。これは、我々の生活習慣・一般常識(共通認識)・社会制度にも関わる話である。今後AIが社会生活に深く浸透し、AI・プロファイリングによる疾病予測(さらには職業適性判断・犯罪リスク予測等)が当たり前になるにつれて、こうした個人に関する「予測データ」も「事実データ」と同等な見られ方をしていく可能性があろう。(文責:吉田絵里香)